Mieszanie spotkań

Rendezvous lub najwyższa losowa waga (HRW) to algorytm osiągnąć rozproszoną zgodę na zestaw z możliwego zestawu opcji. Typową aplikacją jest sytuacja, w której klienci muszą uzgodnić, do których witryn (lub serwerów proxy) przypisane są obiekty.


Spójne mieszanie szczególny przypadek innej metody Mieszanie Rendezvous jest zarówno znacznie prostsze, jak i bardziej ogólne niż spójne mieszanie (patrz poniżej).

Historia
Hashowanie Rendezvous zostało wynalezione przez Davida Thalera i Chinya Ravishankara na Uniwersytecie Michigan w 1996 roku. Konsekwentne haszowanie pojawiło się w literaturze rok później.
Biorąc pod uwagę jego prostotę i ogólność, w rzeczywistych aplikacjach preferowane jest obecnie mieszanie rendezvous zamiast spójnego mieszania. Funkcja mieszania Rendezvous była stosowana bardzo wcześnie w wielu zastosowaniach, w tym w mobilnym buforowaniu, projektowaniu routerów, bezpiecznym ustanawianiu kluczy oraz dzieleniu na fragmenty i rozproszonych bazach danych . Inne przykłady rzeczywistych systemów korzystających z Rendezvous Hashing obejmują moduł równoważenia obciążenia Github, rozproszoną bazę danych Apache Ignite, magazyn plików Tahoe-LAFS, usługę dystrybucji dużych plików CoBlitz, Apache Druid, IBM Cloud Object Store, Arvados Data Management System, Apache Kafka i platforma pub/sub Twitter EventBus.
Jednym z pierwszych zastosowań funkcji mieszania spotkań było umożliwienie klientom multiemisji w Internecie (w kontekstach takich jak MBONE ) identyfikowanie punktów spotkań multiemisji w sposób rozproszony. Był używany w 1998 roku przez protokół Cache Array Routing Protocol (CARP) firmy Microsoft do koordynacji i routingu rozproszonej pamięci podręcznej. Niektóre protokoły routingu Multicast niezależne od protokołu korzystają z funkcji mieszania spotkania w celu wybrania punktu spotkania.
Definicja problemu i podejście
Algorytm
Mieszanie Rendezvous rozwiązuje ogólną wersję problemu rozproszonej tablicy mieszającej : otrzymujemy zestaw (powiedzmy serwery lub serwery proxy) W jaki sposób dowolny zestaw klientów, mając dany obiekt zgodzić się na k- podzbiór witryn, które mają zostać przypisane do ? Standardowa wersja problemu wykorzystuje k = 1. Każdy klient ma dokonać wyboru niezależnie, ale wszyscy muszą wybrać ten sam podzbiór witryn. Nie jest to trywialne, jeśli dodamy do tego minimalne zakłócenia ograniczenia i wymagają, aby w przypadku awarii lub usunięcia witryny jedynie obiekty mapowane na tę witrynę musiały zostać ponownie przypisane do innych witryn.

jest przyznanie każdemu obiektowi ( wagi ) dla każdego obiektu liczbę punktów. Wszyscy klienci najpierw zgadzają się na funkcję skrótu. . Dla obiektu , że miejsce ma wagę . klient _ _ _ które dają k największych wartości skrótu. W ten sposób klienci osiągnęli rozproszony poziom -porozumienie.





Jeśli witryna zostanie dodana lub usunięta, tylko obiekty mapowane na nią minimalnych zakłóceń. zbioru i przypisywany obiekt.


HRW z łatwością dostosowuje różne wydajności w różnych lokalizacjach. Jeśli witryna dwukrotnie większą pojemność niż inne witryny, po prostu reprezentujemy ją razy na liście, powiedzmy, jako } dwa razy więcej obiektów będzie teraz mapowanych na miejsca.


Nieruchomości
Rozważmy prostą wersję problemu, gdzie k = 1, gdzie wszyscy klienci mają zgodzić się na jedną witrynę dla obiektu O. Podchodząc do problemu naiwnie, może się wydawać, że wystarczające będzie traktowanie n witryn jako segmentów w tabeli mieszającej i mieszaniu nazwę obiektu O do tej tabeli. Niestety, jeśli którakolwiek z witryn ulegnie awarii lub będzie nieosiągalna, rozmiar tablicy mieszającej zmienia się, co wymusza ponowne mapowanie wszystkich obiektów. To ogromne zakłócenie sprawia, że takie bezpośrednie mieszanie jest niewykonalne.
Jednak w ramach mieszania spotkania klienci radzą sobie z awariami witryny, wybierając witrynę, która daje kolejną największą wagę. Ponowne mapowanie jest wymagane tylko w przypadku obiektów aktualnie mapowanych na miejsce, w którym wystąpiła awaria, a zakłócenia są minimalne.
Funkcja mieszania Rendezvous ma następujące właściwości:
- Niski narzut: używana funkcja mieszająca jest wydajna, więc obciążenie klientów jest bardzo niskie.
-
Równoważenie obciążenia : Ponieważ funkcja skrótu jest losowa, każda z n witryn ma takie samo prawdopodobieństwo otrzymania obiektu O . Obciążenia są jednakowe we wszystkich lokalizacjach.
- Pojemność lokalizacji: Lokalizacje o różnej wydajności mogą być reprezentowane na liście lokalizacji z wielokrotnością proporcjonalną do pojemności. Ośrodek o dwukrotnie większej przepustowości od pozostałych będzie reprezentowany na liście dwukrotnie, a każdy inny obiekt będzie reprezentowany raz.
- Wysoki współczynnik trafień : Ponieważ wszyscy klienci zgadzają się na umieszczenie obiektu O w tym samym miejscu S O , każde pobranie lub umieszczenie O w S O daje maksymalną użyteczność pod względem współczynnika trafień. Obiekt O zawsze zostanie znaleziony, chyba że zostanie usunięty przez jakiś algorytm zastępujący w S O.
- Minimalne zakłócenia: w przypadku awarii witryny konieczne jest ponowne zmapowanie tylko obiektów zmapowanych na tę witrynę. Jak udowodniono w artykule, zakłócenia są na minimalnym możliwym poziomie.
- Rozproszona umowa k : Klienci mogą osiągnąć rozproszoną umowę w k lokalizacjach, po prostu wybierając k najlepszych witryn w zamówieniu.
Porównanie ze spójnym haszowaniem
Ze względu na swoją prostotę, mniejsze koszty ogólne i ogólność (działa dla każdego k < n ), hashowanie spotkania jest coraz częściej preferowane w stosunku do hashowania spójnego. Najnowsze przykłady jego użycia obejmują moduł równoważenia obciążenia Github, rozproszoną bazę danych Apache Ignite oraz platformę pub/sub Twitter EventBus.
Spójne mieszanie polega na jednolitym i losowym mapowaniu witryn na punkty na okręgu jednostkowym zwane tokenami. Obiekty są również przypisywane do okręgu jednostek i umieszczane w miejscu, którego żeton jest pierwszym napotkanym żetonem, podróżując zgodnie z ruchem wskazówek zegara od lokalizacji obiektu. Kiedy witryna zostanie usunięta, należące do niej obiekty są przenoszone do witryny posiadającej następny napotkany żeton, poruszając się zgodnie z ruchem wskazówek zegara. Zakładając, że każda witryna jest zmapowana na dużą liczbę (powiedzmy 100–200) tokenów, spowoduje to ponowne przypisanie obiektów w stosunkowo jednolity sposób pomiędzy pozostałymi witrynami.
Jeśli witryny są losowo mapowane na punkty na okręgu poprzez mieszanie 200 wariantów identyfikatora witryny, powiedzmy, przypisanie dowolnego obiektu wymaga przechowywania lub ponownego obliczenia 200 wartości skrótu dla każdej witryny. Jednakże tokeny powiązane z daną witryną można wstępnie obliczyć i zapisać na posortowanej liście, co wymaga tylko pojedynczego zastosowania funkcji skrótu do obiektu i wyszukiwania binarnego w celu obliczenia przypisania. Jednak nawet przy wielu tokenach na witrynę podstawowa wersja spójnego mieszania może nie równoważyć równomiernie obiektów w witrynach, ponieważ po usunięciu witryny każdy przypisany do niej obiekt jest rozdzielany tylko na tyle innych witryn, ile witryna ma tokenów (powiedzmy 100 –200).
Warianty spójnego mieszania (takie jak Dynamo firmy Amazon ), które wykorzystują bardziej złożoną logikę do dystrybucji tokenów w okręgu jednostkowym, zapewniają lepsze równoważenie obciążenia niż podstawowe spójne mieszanie, zmniejszają obciążenie związane z dodawaniem nowych witryn i zmniejszają obciążenie metadanymi oraz oferują inne korzyści.
Zalety mieszania Rendezvous w porównaniu z mieszaniem spójnym
Hashowanie Rendezvous (HRW) jest znacznie prostsze koncepcyjnie i w praktyce. Rozmieszcza również obiekty równomiernie we wszystkich witrynach, biorąc pod uwagę jednolitą funkcję skrótu. W przeciwieństwie do spójnego mieszania, HRW nie wymaga wstępnego obliczania ani przechowywania tokenów. Rozważmy k =1. Obiekt umieszczony w jednym z S_ {2} \ poprzez obliczenie wartości skrótu i wybranie witryny , która daje najwyższą wartość skrótu. nowa witryna rozmieszczenia obiektów lub żądania obliczą wybiorą największą z Jeżeli obiekt już znajduje się w systemie przy zostanie pobrany na nowo i zapisany w pamięci podręcznej w S . Odtąd wszyscy będą go uzyskiwać z tej witryny, a stara kopia w pamięci podręcznej ostatecznie zastąpiona algorytmem zarządzania lokalną pamięcią podręczną Jeśli równomiernie odwzorowane na pozostałe witryn.




Warianty algorytmu HRW, takie jak użycie szkieletu (patrz poniżej), mogą skrócić do , kosztem mniejszej globalnej jednolitości rozmieszczenia. Jeśli , koszt umieszczenia podstawowego HRW HRW całkowicie unika wszelkich kosztów ogólnych i złożoności związanych z prawidłową obsługą wielu tokenów dla każdej witryny i powiązanych metadanych.


również tę wielką zaletę, że zapewnia proste rozwiązania innych ważnych problemów, takich jak umowa .
Spójne mieszanie jest szczególnym przypadkiem mieszania Rendezvous
Mieszanie Rendezvous jest zarówno prostsze, jak i bardziej ogólne niż spójne mieszanie. Spójne mieszanie można wykazać jako szczególny przypadek HRW poprzez odpowiedni wybór dwumiejscowej funkcji skrótu. Na podstawie identyfikatora witryny wersja spójnego mieszania oblicza listę pozycji tokenów, np. gdzie miesza wartości z lokalizacjami na okręgu jednostkowym. Zdefiniuj dwumiejscową funkcję skrótu być gdzie oznacza odległość wzdłuż okręgu jednostkowego od do (ponieważ ma pewną minimalną wartość różną od zera, nie ma problemu z przetłumaczeniem tego wartość na unikalną liczbę całkowitą w pewnym ograniczonym zakresie). Spowoduje to dokładne zduplikowanie przypisania utworzonego przez spójne mieszanie.







Nie jest jednak możliwe zredukowanie HRW do spójnego mieszania (zakładając, że liczba tokenów na witrynę jest ograniczona), ponieważ HRW potencjalnie ponownie przypisuje obiekty z usuniętej witryny do nieograniczonej liczby innych witryn.
Ważone różnice
W standardowej implementacji mieszania spotkania każdy węzeł otrzymuje statycznie równą część kluczy. To zachowanie jest jednak niepożądane, gdy węzły mają różną zdolność przetwarzania lub przechowywania przypisanych im kluczy. Na przykład, jeśli jeden z węzłów miałby dwukrotnie większą pojemność niż pozostałe, korzystne byłoby, gdyby algorytm wziął to pod uwagę w taki sposób, aby ten silniejszy węzeł otrzymał dwukrotnie większą liczbę kluczy niż każdy z pozostałych.
Prostym mechanizmem obsługi tego przypadku jest przypisanie do tego węzła dwóch lokalizacji wirtualnych, tak że jeśli którakolwiek z wirtualnych lokalizacji tego większego węzła ma najwyższy skrót, węzeł ten otrzyma klucz. Jednak ta strategia nie działa, gdy wagi względne nie są wielokrotnościami całkowitymi. Na przykład, jeśli jeden węzeł miałby o 42% większą pojemność pamięci, wymagałoby to dodania wielu wirtualnych węzłów w różnych proporcjach, co doprowadziłoby do znacznego zmniejszenia wydajności. Zaproponowano kilka modyfikacji funkcji mieszania spotkań, aby przezwyciężyć to ograniczenie.
Protokół routingu tablicy pamięci podręcznej
Protokół Cache Array Routing Protocol (CARP) to wersja robocza IETF z 1998 r., która opisuje metodę obliczania współczynników obciążenia , które można pomnożyć przez wynik mieszania każdego węzła, aby uzyskać dowolny poziom precyzji dla różnych wag węzłów. Jednakże wadą tego podejścia jest to, że w przypadku zmiany wagi dowolnego węzła lub dodania lub usunięcia dowolnego węzła wszystkie współczynniki obciążenia muszą zostać ponownie obliczone i odpowiednio przeskalowane. Kiedy współczynniki obciążenia zmieniają się względem siebie, powoduje to ruch kluczy pomiędzy węzłami, których waga nie uległa zmianie, ale których współczynnik obciążenia zmienił się w stosunku do innych węzłów w systemie. Powoduje to nadmierny ruch klawiszy.
Kontrolowana replikacja
Kontrolowana replikacja w ramach skalowalnego mieszania lub CRUSH to rozszerzenie RUSH, które ulepsza funkcję mieszania spotkania poprzez konstruowanie drzewa, w którym funkcja pseudolosowa (hash) jest używana do poruszania się w dół drzewa w celu ustalenia, który węzeł jest ostatecznie odpowiedzialny za dany klucz. Zapewnia doskonałą stabilność podczas dodawania węzłów, jednak nie jest idealnie stabilna podczas usuwania lub ponownego ważenia węzłów, przy czym nadmierny ruch kluczy jest proporcjonalny do wysokości drzewa.
Algorytm CRUSH jest wykorzystywany przez system przechowywania danych ceph do mapowania obiektów danych do węzłów odpowiedzialnych za ich przechowywanie.
Wariant oparty na szkielecie
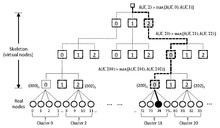
Kiedy jest , wariant oparty na szkielecie może skrócić czas działania. To podejście tworzy wirtualną strukturę i pozwala uzyskać czas działania, hierarchii. Pomysł jest taki, aby najpierw wybrać uporządkować w klastry wybierając stałą wyobrażając sobie te na liściach drzewa wirtualnych węzłów, każdy .






Na załączonym diagramie rozmiar klastra wynosi { = Zakładając dla wygody 108 lokalizacji (rzeczywistych węzłów), otrzymujemy trójpoziomową hierarchię wirtualną. Ponieważ ma naturalną numerację w formacie ósemkowym Zatem 27 węzłów wirtualnych na najniższym poziomie będzie miało numery ósemkowo (możemy oczywiście zmieniać rozłożenie na każdym poziomie - w takim przypadku każdy węzeł zostanie zidentyfikowany za pomocą odpowiedniego numeru o



Zamiast stosować HRW do wszystkich 108 rzeczywistych węzłów, możemy najpierw zastosować HRW do 27 wirtualnych węzłów najniższego poziomu, wybierając jeden. Następnie stosujemy HRW do czterech rzeczywistych węzłów w klastrze i wybieramy zwycięską lokalizację. Potrzebujemy tylko wyżej w hierarchii, potrzebowalibyśmy skróty, aby dostać się do zwycięskiej witryny. zaczynając od korzenia szkieletu wybierać i i ostatecznie kończy się na witrynie 74.





Możemy zacząć od dowolnego poziomu wirtualnej hierarchii, a nie tylko od korzenia. Rozpoczęcie pracy niżej w hierarchii wymaga większej liczby skrótów, ale może poprawić rozkład obciążenia w przypadku awarii. Ponadto hierarchia wirtualna nie musi być przechowywana, ale można ją utworzyć na żądanie, ponieważ nazwy węzłów wirtualnych są po prostu przedrostkami reprezentacji podstawowych ( o mieszanej podstawie) W razie potrzeby z cyfr możemy łatwo utworzyć odpowiednio posortowane ciągi znaków. W tym przykładzie pracowalibyśmy z ciągami znaków na poziomie 1), na i Jasne jest, ma wysokość. , ponieważ i obie są stałymi. Praca wykonana ponieważ .





że metoda wybiera każdy klaster, a tym samym każde z miejsc, z równym prawdopodobieństwem Jeśli ostatecznie wybrana lokalizacja jest niedostępna, możemy w zwykły sposób wybrać inną lokalizację w tym samym klastrze. Alternatywnie możemy przejść w górę o jeden lub więcej poziomów w szkielecie i wybrać alternatywny spośród równorzędnych węzłów wirtualnych na tym poziomie, a następnie ponownie zejść w dół hierarchii do węzłów rzeczywistych, jak powyżej.
Wartość można wybrać na podstawie czynników takich jak przewidywany wskaźnik awaryjności i stopień pożądanego równoważenia Wyższa wartość kosztem większego narzutu na wyszukiwanie.
Wybór mieszaniu spotkań funkcja skrótu , więc może działać całkiem bardzo


Inne warianty
W 2005 roku Christian Schindelhauer i Gunnar Schomaker opisali logarytmiczną metodę ponownego ważenia wyników skrótu w sposób, który nie wymaga względnego skalowania współczynników obciążenia, gdy zmienia się waga węzła lub gdy węzły są dodawane lub usuwane. Zapewniło to podwójne korzyści w postaci doskonałej precyzji ważenia węzłów, a także doskonałej stabilności, ponieważ tylko minimalna liczba kluczy wymagała ponownego przypisania do nowych węzłów.
Podobna strategia mieszania oparta na logarytmach jest używana do przypisywania danych do węzłów przechowywania w systemie przechowywania danych Cleversafe , obecnie IBM Cloud Object Storage .
Systemy korzystające z funkcji mieszania Rendezvous
Rendezvous Hashing jest szeroko stosowany w systemach świata rzeczywistego. Częściowa lista obejmuje bazę danych Oracle w pamięci, moduł równoważenia obciążenia Github, rozproszoną bazę danych Apache Ignite, magazyn plików Tahoe-LAFS, usługę dystrybucji dużych plików CoBlitz, Apache Druid, IBM Cloud Object Store, Arvados Data Management System, Apache Kafka oraz platformę wydawniczą/subskrypcyjną Twitter EventBus.
Realizacja
Implementacja jest prosta po wybraniu funkcji skrótu oryginalna praca nad metodą HRW zawiera zalecenie dotyczące Każdy klient musi jedynie obliczyć wartość skrótu dla każdej z następnie wybrać największą. Algorytm . Jeśli funkcja skrótu jest wydajna, czas pracy nie stanowi problemu, chyba że .
Ważony skrót spotkania
Kod Pythona implementujący ważony skrót spotkania:
importuj mmh3 importuj matematykę z klas danych importuj klasę danych z wpisania import List def hash_to_unit_interval ( s : str ) -> float : """Haszuje ciąg znaków do interwału jednostkowego (0, 1]""" return ( mmh3 . hash128 ( s ) + 1 ) / 2 ** 128
@dataclass class Node : """Klasa reprezentująca węzeł, któremu przypisano klucze w ramach ważonego skrótu spotkania.""" name : str waga : float def compute_weighted_score ( self , key : str ): score = hash_to_unit_interval ( f " { nazwa własna } : { klucz } " _
) log_score = 1,0 / - math . log ( wynik ) zwróć siebie . waga * log_score def determin_responsible_node ( nodes : lista [ węzeł ], klucz : str ): """Określa, który węzeł zbioru węzłów o różnych wagach jest odpowiedzialny za podany klucz.""" return max ( węzły , klucz = węzeł lambda : węzeł . compute_weighted_score ( klucz ), domyślnie = Brak )
Przykładowe wyjścia WRH:
>>> import wrh >>> węzeł1 = wrh . Węzeł ( „węzeł1” , 100 ) >>> węzeł2 = wrh . Węzeł ( „węzeł2” , 200 ) >>> węzeł3 = wrh . Węzeł ( „węzeł3” , 300 ) >>> str ( wrh .
określić_odpowiedzialny_node ([ węzeł1 , węzeł2 , węzeł3 ], "foo" )) "Węzeł(nazwa='węzeł1', waga=100)" >>> str ( wrh . określ_responsible_node ([ węzeł1 , węzeł2 , węzeł3 ], "bar" ) ) "Węzeł(nazwa='węzeł2', waga=300)" >>> str ( wrh . Określ_odpowiedzialny_węzeł
([ węzeł1 , węzeł2 , węzeł3 ], "cześć" )) "Węzeł(nazwa='węzeł2', waga=300)" >>> węzły = [ węzeł1 , węzeł2 , węzeł3 ] >>> z kolekcji Licznik importu >>> odpowiedzialne_nodes = [ wrh . create_responsible_node ( ... węzły , np
„klucz: { klawisz } ” ) . nazwa klucza w zakresie ( 45_000 )] >>> print ( Licznik ( odpowiedzialne_węzły )) Licznik({'node3': 22487, ' node2 ': 15020, 'node1': 7493})