paradoks Lindleya
Paradoks Lindleya to sprzeczna z intuicją sytuacja w statystyce , w której podejście bayesowskie i częstościowe do problemu testowania hipotez daje różne wyniki dla pewnych wyborów wcześniejszego rozkładu . Problem niezgodności między tymi dwoma podejściami został omówiony w podręczniku Harolda Jeffreysa z 1939 r.; stało się znane jako paradoks Lindleya po tym, jak Dennis Lindley nazwał ten spór paradoksem w artykule z 1957 roku.
Chociaż określane jako paradoks , różne wyniki z podejścia bayesowskiego i częstościowego można wyjaśnić raczej jako wykorzystanie ich do odpowiedzi na zasadniczo różne pytania, niż rzeczywistą niezgodę między tymi dwiema metodami.
Niemniej jednak dla dużej klasy przeorów różnice między podejściem częstości a podejściem bayesowskim wynikają z utrzymywania stałego poziomu istotności: jak zauważył nawet Lindley, „teoria nie usprawiedliwia praktyki utrzymywania stałego poziomu istotności”, a nawet „niektórzy obliczenia przeprowadzone przez prof. szybko, to rozbieżność między podejściem częstościowym a podejściem bayesowskim staje się nieistotna wraz ze wzrostem wielkości próby.
Opis paradoksu
Wynik ma dwa możliwe wyjaśnienia, hipotezy i oraz pewną wcześniejszą dystrybucję reprezentujący niepewność co do tego, która hipoteza jest dokładniejsza przed wzięciem pod uwagę .




Paradoks Lindleya występuje, gdy
- Wynik jest „znaczący” w teście częstości , wskazującym na wystarczające dowody, aby odrzucić, { na poziomie 5%, oraz
- Podane późniejsze prawdopodobieństwo mocne dowody na to, że lepiej zgadza się z \ niż .
gdy jest bardzo specyficzny, bardziej rozproszony, a wcześniejsza dystrybucja nie faworyzuje silnie jednego inne, jak widać poniżej.
Przykład liczbowy
Poniższy przykład liczbowy ilustruje paradoks Lindleya. W pewnym mieście w pewnym okresie urodziło się 49 581 chłopców i 48 870 dziewczynek. Obserwowany odsetek wynosi zatem 49 581/98 451 ≈ 0,5036. Zakładamy, że ułamek urodzeń chłopców jest zmienną dwumianową z parametrem . Jesteśmy zainteresowani sprawdzeniem, czy , czy jakaś inna wartość. Oznacza to, że nasza hipoteza zerowa to , a alternatywą jest .



Podejście frekwencjonistyczne
Częstym podejściem do testowania obliczenie wartości p , prawdopodobieństwa zaobserwowania ułamka chłopców co najmniej tak dużego, jak przy założeniu, że jest prawdziwe. Ponieważ liczba urodzeń jest bardzo duża, możemy zastosować przybliżenie normalne dla ułamka urodzeń mężczyzn z i _




Bylibyśmy równie zaskoczeni, gdybyśmy widzieli 49 581 urodzeń płci żeńskiej, tj zwykle przeprowadzałby test dwustronny , dla którego wartość p wynosiłaby . W obu przypadkach wartość p jest niższa niż poziom istotności α wynoszący 5%, więc podejście częstości odrzuca ponieważ nie zgadza się z obserwowanymi danymi.


podejście bayesowskie
bayesowskie polegałoby na przypisaniu równomierny rozkład do poniżej obliczyć późniejsze prawdopodobieństwo za pomocą Twierdzenie Bayesa ,



Po zaobserwowaniu z późniejsze prawdopodobieństwo funkcji zmienna dwumianowa,



gdzie jest funkcją Beta .

Na podstawie tych wartości znajdujemy późniejsze prawdopodobieństwo , co zdecydowanie faworyzuje nad .

Te dwa podejścia - bayesowskie i częstościowe - wydają się być w konflikcie i to jest „paradoks”.
Pogodzenie podejścia bayesowskiego i częstościowego
Prawie pewne testowanie hipotez
Naaman zaproponował dostosowanie poziomu istotności do liczebności próby w celu kontroli wyników fałszywie dodatnich: α n , takie, że α n = n − r gdzie r > 1/2 . Przynajmniej w przykładzie numerycznym przyjęcie r = 1/2 daje poziom istotności 0,00318, więc bywalca nie odrzuciłby hipotezy zerowej, co jest zgodne z podejściem bayesowskim.
Nieinformacyjne przeorki
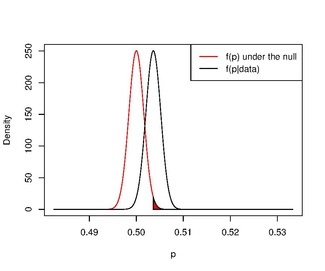
Jeśli użyjemy nieinformacyjnego przeoru i przetestujemy hipotezę bardziej podobną do tej w podejściu częstościowym, paradoks zniknie.
obliczymy _ _ tj. ), znajdujemy

![\textstyle \pi(\theta \in [0,1]) = 1](https://wikimedia.org/api/rest_v1/media/math/render/svg/755f6338d2d6c0f581f1af23bb772dd9dd2acadc)

Jeśli użyjemy tego do sprawdzenia prawdopodobieństwa, że noworodek z większym prawdopodobieństwem będzie chłopcem niż dziewczynką, tj. } znaleźliśmy


Innymi słowy, jest bardzo prawdopodobne, że odsetek urodzeń płci męskiej przekroczy 0,5.
Żadna analiza nie daje bezpośredniego oszacowania wielkości efektu , ale obie można wykorzystać do określenia, na przykład, czy odsetek urodzeń chłopców prawdopodobnie przekroczy jakiś określony próg.
Brak rzeczywistego paradoksu
Pozorna niezgodność między tymi dwoma podejściami jest spowodowana kombinacją czynników. Po , powyższe podejście częstości testuje bez odniesienia do . Podejście bayesowskie ocenia alternatywę dla i stwierdza obserwacjami Dzieje się tak, ponieważ ta druga hipoteza jest znacznie bardziej rozproszona, ponieważ może znajdować się w dowolnym miejscu w , co powoduje, że ma bardzo niskie prawdopodobieństwo późniejsze. Aby zrozumieć dlaczego, pomocne jest rozważenie dwóch hipotez jako generatorów obserwacji:
![\textstyle [0, 1]](https://wikimedia.org/api/rest_v1/media/math/render/svg/bbfdf72e3d8918aa908f51a9d4b5ed68bea1bc0b)
- Pod wybieramy i pytamy że zobaczymy 49 581 chłopców w 98 451
- Pod , wybieramy 1 i zadajemy to samo pytanie

możliwych wartości bardzo słabo obserwacjami Zasadniczo pozorna niezgodność między metodami wcale nie jest niezgodą, ale raczej dwoma różnymi stwierdzeniami dotyczącymi tego, w jaki sposób hipotezy odnoszą się do danych:
- Bywalca stwierdza, że słabe wyjaśnienie obserwacji.
- Bayesian stwierdza, że jest to znacznie lepsze wyjaśnienie obserwacji niż .
Stosunek płci noworodków wynosi nieprawdopodobnie 50/50 płci męskiej i żeńskiej, zgodnie z testem częstości. Jednak 50/50 jest lepszym przybliżeniem niż większość innych wskaźników, ale nie wszystkie . Hipoteza pasowałaby do obserwacji znacznie lepiej niż prawie wszystkie inne wskaźniki, w tym 0,504

Na przykład ten wybór hipotez i wcześniejszych prawdopodobieństw implikuje stwierdzenie: „jeśli > 0,49 i < 0,51, to wcześniejsze prawdopodobieństwo równe 0,5 to 0,50/0,51 98%. Biorąc pod tak silną preferencję dla , łatwo zrozumieć, dlaczego podejście bayesowskie faworyzuje w obliczu , mimo że obserwowana wartość 2,28 od 0,5. Odchylenie o ponad 2 sigma od uważane za znaczące w podejściu częstościowym, ale jego znaczenie jest unieważniane przez przeor w podejściu bayesowskim







to z innej strony, możemy zobaczyć, że poprzedni rozkład jest zasadniczo płaski z delta Oczywiście jest to wątpliwe. W rzeczywistości, gdybyś miał wyobrazić sobie liczby rzeczywiste jako ciągłe, bardziej logiczne byłoby założenie, że żadna dana liczba nie byłaby dokładnie taką samą wartością parametru, tj. powinniśmy założyć, że P .


Bardziej realistyczny rozkład dla w alternatywnej daje mniej zaskakujący wynik dla tylnej części . Na przykład, jeśli zastąpimy przez , tj. oszacowanie maksymalnego prawdopodobieństwa dla , późniejsze prawdopodobieństwo wyniosłoby tylko 0,07 w porównaniu do 0,93 dla (Oczywiście faktycznie używać MLE jako części wcześniejsza dystrybucja).


Ostatnia dyskusja
Paradoks nadal jest źródłem aktywnej dyskusji.
Zobacz też
Notatki
Dalsza lektura
- Shafer, Glenn (1982). „Paradoks Lindleya”. Dziennik Amerykańskiego Towarzystwa Statystycznego . 77 (378): 325–334. doi : 10.2307/2287244 . JSTOR 2287244 . MR 0664677 .