Częstotliwość liter
| List | Częstotliwość względna w języku angielskim | |||
|---|---|---|---|---|
| Teksty | Słowniki | |||
| A | 8,2% |
|
7,8% |
|
| B | 1,5% |
|
2% |
|
| C | 2,8% |
|
4% |
|
| D | 4,3% |
|
3,8% |
|
| mi | 13% |
|
11% |
|
| F | 2,2% |
|
1,4% |
|
| G | 2% |
|
3% |
|
| H | 6,1% |
|
2,3% |
|
| I | 7% |
|
8,6% |
|
| J | 0,15% |
|
0,21% |
|
| k | 0,77% |
|
0,97% |
|
| Ł | 4% |
|
5,3% |
|
| M | 2,4% |
|
2,7% |
|
| N | 6,7% |
|
7,2% |
|
| O | 7,5% |
|
6,1% |
|
| P | 1,9% |
|
2,8% |
|
| Q | 0,095% |
|
0,19% |
|
| R | 6% |
|
7,3% |
|
| S | 6,3% |
|
8,7% |
|
| T | 9,1% |
|
6,7% |
|
| u | 2,8% |
|
3,3% |
|
| V | 0,98% |
|
1% |
|
| W | 2,4% |
|
0,91% |
|
| X | 0,15% |
|
0,27% |
|
| Y | 2% |
|
1,6% |
|
| Z | 0,074% |
|
0,44% |
|
występowania liter to średnia liczba wystąpień liter alfabetu w języku pisanym . Analiza częstotliwości liter sięga arabskiego matematyka Al-Kindi (ok. 801–873 ne), który formalnie opracował metodę łamania szyfrów . Analiza częstotliwości liter zyskała na znaczeniu w Europie wraz z rozwojem ruchomych czcionek w 1450 r., Kiedy to należy oszacować ilość czcionek wymaganych dla każdego kształtu litery . Lingwiści wykorzystują analizę częstotliwości liter jako podstawową technikę identyfikacji języka , gdzie jest ona szczególnie skuteczna jako wskazanie, czy nieznany system pisma jest alfabetyczny, sylabiczny czy ideograficzny .
Wykorzystanie częstotliwości liter i analizy częstotliwości odgrywa fundamentalną rolę w kryptogramach i kilku łamigłówkach słownych, w tym Hangman , Scrabble , Wordle i teleturnieju Wheel of Fortune . Jeden z najwcześniejszych opisów w literaturze klasycznej zastosowania znajomości częstotliwości liter angielskich do rozwiązania kryptogramu znajduje się w słynnej opowieści Edgara Allana Poe The Gold-Bug , gdzie metoda ta z powodzeniem została zastosowana do rozszyfrowania wiadomości podającej lokalizację skarbu ukrytego przez kapitana Kidda . [ potrzebne źródło ]
Herbert S. Zim w swoim klasycznym wprowadzającym tekście kryptograficznym „Codes and Secret Writing” podaje sekwencję częstotliwości angielskich liter jako „ ETAON RISHD LFCMU GYPWB VKJXZQ ”, najczęstsze pary liter jako „TH HE AN RE ER IN ON AT ND ST ES EN OF TE ED OR TI HI AS TO”, a najczęstsze podwójne litery to „LL EE SS OO TT FF RR NN PP CC”. Różne sposoby liczenia mogą dawać nieco inne zamówienia.
Częstotliwości liter mają również duży wpływ na projekt niektórych układów klawiatury . Najczęstsze litery są umieszczane w głównym rzędzie maszyny do pisania Blickensderfer , układzie klawiatury Dvorak , Colemak i innych zoptymalizowanych układach.
Tło

Częstotliwość liter w tekście była badana pod kątem wykorzystania w kryptoanalizie , aw szczególności analizie częstotliwości , począwszy od arabskiego matematyka Al-Kindi (ok. 801–873 ne), który formalnie opracował metodę (szyfry łamliwe tą techniką wróć przynajmniej do szyfru Cezara wymyślonego przez Juliusza Cezara , więc metoda ta mogła być badana w czasach klasycznych). Analiza częstotliwości liter zyskała dodatkowe znaczenie w Europie wraz z rozwojem ruchomych czcionek w 1450 r., Kiedy to należy oszacować ilość czcionek wymaganych dla każdego kształtu litery, o czym świadczą różnice w wielkości przegródek na litery w skrzynkach typograficznych.
Żaden dokładny rozkład częstotliwości liter nie leży u podstaw danego języka, ponieważ wszyscy pisarze piszą nieco inaczej. Jednak większość języków ma charakterystyczny rozkład, który jest wyraźnie widoczny w dłuższych tekstach. Nawet zmiany językowe tak skrajne, jak przejście od staroangielskiego do współczesnego angielskiego (uważane za wzajemnie niezrozumiałe) wykazują silne tendencje w częstotliwości powiązanych liter: na niewielkiej próbce fragmentów biblijnych, od najczęstszych do najrzadziej występujących, enaid sorhm tgþlwu æcfy ðbpxz ze staroangielskiego porównuje do eotha sinrd luymw fgcbp kvjqxz współczesnego angielskiego, z najbardziej skrajnymi różnicami dotyczącymi form liter, które nie są wspólne.
Maszyny linotypowe dla języka angielskiego przyjęły kolejność liter, od najbardziej do najmniej powszechnej, jako etaoin shrdlu cmfwyp vbgkjq xz na podstawie doświadczenia i zwyczajów ręcznych kompozytorów. Odpowiednikiem dla języka francuskiego było elaoin sdrétu cmfhyp vbgwqj xz .
Ułożenie alfabetu Morse'a w grupy liter, których przesłanie wymaga równej ilości czasu, a następnie posortowanie tych grup w kolejności rosnącej, daje e it san hurdm wgvlfbk opxcz jyq . Częstotliwość liter była używana przez inne systemy telegraficzne, takie jak kod Murraya .
Podobne pomysły są wykorzystywane w nowoczesnych technikach kompresji danych, takich jak kodowanie Huffmana .
Częstotliwości liter, podobnie jak częstotliwości słów , różnią się, zarówno w zależności od autora, jak i tematu. Nie można napisać eseju o promieniach rentgenowskich bez częstego używania ⟨x⟩, a esej będzie miał specyficzną częstotliwość liter, jeśli esej dotyczy wykorzystania promieni rentgenowskich do leczenia zebr w Katarze . Różni autorzy mają nawyki, które można odzwierciedlić w używaniu przez nich liter. Na przykład styl pisania Hemingwaya wyraźnie różni się od stylu Faulknera . Litera, bigram , trygram , częstotliwość słów, długość słów i długość zdań można obliczyć dla konkretnych autorów i wykorzystać do udowodnienia lub obalenia autorstwa tekstów, nawet w przypadku autorów, których style nie są tak rozbieżne.
Dokładne średnie częstotliwości występowania liter można uzyskać jedynie poprzez analizę dużej ilości reprezentatywnego tekstu. Dzięki dostępności nowoczesnych komputerów i zbiorów dużych korpusów tekstowych takie obliczenia są łatwe do wykonania. Przykłady można czerpać z różnych źródeł (reportaże prasowe, teksty religijne, teksty naukowe i beletrystyka ogólna) i istnieją różnice, zwłaszcza w przypadku fikcji ogólnej z pozycją ⟨h⟩ i ⟨i⟩, przy czym ⟨h⟩ staje się coraz bardziej powszechne.
Należy również zauważyć, że różne dialekty języka również będą miały wpływ na częstotliwość litery. Na przykład autor w Stanach Zjednoczonych stworzyłby coś, w czym ⟨z⟩ jest bardziej powszechne niż autor w Wielkiej Brytanii piszący na ten sam temat: słowa takie jak „analizować”, „przepraszać” i „rozpoznawać” zawierają literę w amerykańskim angielskim, podczas gdy te same słowa są pisane jako „analizować”, „przepraszać” i „rozpoznawać” w brytyjskim angielskim. Miałoby to duży wpływ na częstotliwość litery ⟨z⟩, ponieważ jest to litera rzadko używana przez Brytyjczyków w języku angielskim.
„Pierwsze dwanaście” liter stanowi około 80% całkowitego wykorzystania. „Osiem pierwszych” liter stanowi około 65% całkowitego wykorzystania. najlepsza jest dwuparametrowa funkcja rangi Cocho/Beta . Inna funkcja rangi bez regulowanego wolnego parametru również dość dobrze pasuje do rozkładu częstotliwości liter (ta sama funkcja została użyta do dopasowania częstotliwości aminokwasów w sekwencjach białkowych). Szpieg używający szyfru VIC lub inny szyfr oparty na rozciągniętej szachownicy zazwyczaj używa mnemonika, takiego jak „grzech do błędu” (pominięcie drugiego „r”) lub „na jednego pana”, aby zapamiętać osiem pierwszych znaków.
Względne częstotliwości liter w języku angielskim

Istnieją trzy sposoby liczenia częstotliwości liter, które dają bardzo różne wykresy dla wspólnych liter. Pierwsza metoda, zastosowana na poniższym wykresie, polega na zliczeniu częstotliwości występowania liter w słowach źródłowych słownika. Drugim jest uwzględnienie wszystkich wariantów słów podczas liczenia, takich jak „streszczenia”, „abstrakcja” i „abstrakcja”, a nie tylko rdzeń słowa „streszczenie”. Ten system powoduje, że litery takie jak ⟨s⟩ pojawiają się znacznie częściej, na przykład podczas liczenia liter z list najczęściej używanych angielskich słów w Internecie. Ostatnim wariantem jest liczenie liter na podstawie częstotliwości ich używania w rzeczywistych tekstach, w wyniku czego niektóre kombinacje liter, takie jak ⟨th⟩, stają się bardziej powszechne ze względu na częste używanie popularnych słów, takich jak „the”, „then”, „oba”, „to” itp. Miary bezwzględnej częstotliwości użytkowania, takie jak ta, są używane podczas tworzenia układów klawiatury lub częstotliwości liter w staromodnych prasach drukarskich.
Analiza haseł w słowniku Concise Oxford, pomijając częstotliwość używania słów, daje kolejność „EARIOTNSLCUDPMHGBFYWKVXZJQ”.
Poniższa tabela częstotliwości liter pochodzi ze strony internetowej Pavla Mički, która cytuje Cryptological Mathematics Roberta Lewanda .
Według Lewanda, ułożone od najbardziej do najmniej powszechnych w wyglądzie, litery to: etaoinshrdlcumwfgypbvkjxqz . Kolejność Lewanda różni się nieco od innych, takich jak projekt Cornell University Math Explorer, który stworzył tabelę po zmierzeniu 40 000 słów.
W języku angielskim znak spacji występuje prawie dwa razy częściej niż górna litera (⟨e⟩), a znaki niealfabetyczne (cyfry, znaki interpunkcyjne itp.) łącznie zajmują czwartą pozycję (po uwzględnieniu spacji) między ⟨t⟩ i ⟨a⟩.
Względne częstotliwości pierwszych liter słowa w języku angielskim
| List | Częstotliwość względna jako pierwsza litera angielskiego słowa [ potrzebne źródło ] | |||
|---|---|---|---|---|
| Teksty | Słowniki | |||
| A | 11,7% |
|
5,7% |
|
| B | 4,4% |
|
6% |
|
| C | 5,2% |
|
9,4% |
|
| D | 3,2% |
|
6,1% |
|
| mi | 2,8% |
|
3,9% |
|
| F | 4% |
|
4,1% |
|
| G | 1,6% |
|
3,3% |
|
| H | 4,2% |
|
3,7% |
|
| I | 7,3% |
|
3,9% |
|
| J | 0,51% |
|
1,1% |
|
| k | 0,86% |
|
1% |
|
| Ł | 2,4% |
|
3,1% |
|
| M | 3,8% |
|
5,6% |
|
| N | 2,3% |
|
2,2% |
|
| O | 7,6% |
|
2,5% |
|
| P | 4,3% |
|
7,7% |
|
| Q | 0,22% |
|
0,49% |
|
| R | 2,8% |
|
6% |
|
| S | 6,7% |
|
11% |
|
| T | 16% |
|
5% |
|
| u | 1,2% |
|
2,9% |
|
| V | 0,82% |
|
1,5% |
|
| W | 5,5% |
|
2,7% |
|
| X | 0,045% |
|
0,05% |
|
| Y | 0,76% |
|
0,36% |
|
| Z | 0,045% |
|
0,24% |
|
Częstotliwość pierwszych liter słów lub nazw jest pomocna przy wstępnym przydzielaniu miejsca w plikach fizycznych i indeksach. W przypadku 26 szafy na akta , zamiast przypisywania jednej szuflady do jednej litery alfabetu w stosunku 1:1, często przydatne jest zastosowanie kodu literowego o większej częstotliwości, przypisując kilka liter o niskiej częstotliwości do tej samej szuflady (często jedna szuflada jest oznaczona jako VWXYZ) oraz rozbicie najczęściej występujących liter początkowych (⟨s, a, c⟩) na kilka szuflad (często 6 szuflad Aa-An, Ao-Az, Ca-Cj, Ck-Cz, Sa -Si, Sj-Sz). Ten sam system jest używany w niektórych pracach wielotomowych, takich jak niektóre encyklopedie . Numery frezów , inne odwzorowanie nazw na kod o bardziej równej częstotliwości, są używane w niektórych bibliotekach.
Zarówno ogólny rozkład liter, jak i rozkład liter początkowych w przybliżeniu odpowiadają rozkładowi Zipf , a jeszcze bardziej pasują do rozkładu Yule .
Często rozkład częstotliwości pierwszej cyfry w każdym układzie odniesienia znacznie różni się od ogólnej częstotliwości wszystkich cyfr w zbiorze danych liczbowych, szczegółowe informacje można znaleźć w prawie Benforda .
Analiza przeprowadzona przez Petera Norviga w danych Google Books określiła między innymi częstotliwość pierwszych liter angielskich słów.
Analiza z czerwca 2012 r. Przy użyciu dokumentu tekstowego zawierającego wszystkie słowa w języku angielskim dokładnie raz wykazała, że ⟨s⟩ jest najczęstszą literą początkową słów w języku angielskim, po której następuje ⟨p, c, a⟩.
Względne częstotliwości liter w innych językach
| List |
angielski [ potrzebne źródło ] |
Francuski | Niemiecki | hiszpański | portugalski | esperanto | Włoski | turecki | szwedzki | Polski | Holenderski | duński | islandzki | fiński |
czeski [ potrzebne źródło ] |
język węgierski |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| A | 8,167% | 7,636% | 6,516% | 11,525% | 14,634% | 12,117% | 11,745% | 11,920% | 9,383% | 8,965% | 7,49% | 6,025% | 10,110% | 12,217% | 8,421% | 10,778% |
| B | 1,492% | 0,901% | 1,886% | 2,215% | 1,043% | 0,980% | 0,927% | 2,844% | 1,535% | 1,482% | 1,58% | 2.000% | 1,043% | 0,281% | 0,822% | 2,647% |
| C | 2,782% | 3,260% | 2,732% | 4,019% | 3,882% | 0,776% | 4,501% | 0,963% | 1,486% | 3,988% | 1,24% | 0,565% | ~0% | 0,281% | 0,740% | 0,924% |
| D | 4,253% | 3,669% | 5,076% | 5,010% | 4,992% | 3,044% | 3,736% | 4,706% | 4,702% | 3,293% | 5,93% | 5,858% | 1,575% | 1,043% | 3,475% | 2,410% |
| mi | 12,702% | 14,715% | 16,396% | 12,181% | 12,570% | 8,995% | 11,792% | 8,912% | 10,149% | 7,921% | 18,91% | 15,453% | 6,418% | 7,968% | 7,562% | 11,926% |
| F | 2,228% | 1,066% | 1,656% | 0,692% | 1,023% | 1,037% | 1,153% | 0,461% | 2,027% | 0,312% | 0,81% | 2,406% | 3,013% | 0,194% | 0,084% | 1,221% |
| G | 2,015% | 0,866% | 3,009% | 1,768% | 1,303% | 1,171% | 1,644% | 1,253% | 2,862% | 1,377% | 3,40% | 4,077% | 4,241% | 0,392% | 0,092% | 3,650% |
| H | 6,094% | 0,737% | 4,577% | 0,703% | 0,781% | 0,384% | 0,636% | 1,212% | 2,090% | 1,072% | 2,38% | 1,621% | 1,871% | 1,851% | 1,356% | 1,568% |
| I | 6,966% | 7,529% | 6,550% | 6,247% | 6,186% | 10,012% | 10,143% | 8.600%* | 5,817% | 8,286% | 6,50% | 6.000% | 7,578% | 10,817% | 6,073% | 5,343% |
| J | 0,153% | 0,613% | 0,268% | 0,493% | 0,397% | 3,501% | 0,011% | 0,034% | 0,614% | 2,343% | 1,46% | 0,730% | 1,144% | 2,042% | 1,433% | 1,321% |
| k | 0,772% | 0,074% | 1,417% | 0,011% | 0,015% | 4,163% | 0,009% | 4,683% | 3,140% | 3,411% | 2,25% | 3,395% | 3,314% | 4,973% | 2,894% | 5,939% |
| l | 4,025% | 5,456% | 3,437% | 4,967% | 2,779% | 6,104% | 6,510% | 5,922% | 5,275% | 2,136% | 3,57% | 5,229% | 4,532% | 5,761% | 3,802% | 7,464% |
| M | 2,406% | 2,968% | 2,534% | 3,157% | 4,738% | 2,994% | 2,512% | 3,752% | 3,471% | 2,911% | 2,21% | 3,237% | 4,041% | 3,202% | 2,446% | 3,621% |
| N | 6,749% | 7,095% | 9,776% | 6,712% | 4,446% | 7,955% | 6,883% | 7,487% | 8,542% | 5.600% | 10,03% | 7,240% | 7,711% | 8,826% | 6,468% | 6,472% |
| o | 7,507% | 5,796% | 2,594% | 8,683% | 9,735% | 8,779% | 9,832% | 2,476% | 4,482% | 7,590% | 6,06% | 4,636% | 2,166% | 5,614% | 6,695% | 4,62% |
| P | 1,929% | 2,521% | 0,670% | 2,510% | 2,523% | 2,755% | 3,056% | 0,886% | 1,839% | 3,101% | 1,57% | 1,756% | 0,789% | 1,842% | 1,906% | 1,573% |
| Q | 0,095% | 1,362% | 0,018% | 0,877% | 1,204% | 0 | 0,505% | 0 | 0,020% | 0,003% | 0,009% | 0,007% | 0 | 0,013% | 0,001% | 0,014% |
| R | 5,987% | 6,693% | 7,003% | 6,871% | 6,530% | 5,914% | 6,367% | 6,722% | 8,431% | 4,571% | 6,41% | 8,956% | 8,581% | 2,872% | 4,799% | 5,188% |
| S | 6,327% | 7,948% | 7,270% | 7,977% | 6,805% | 6,092% | 4,981% | 3,014% | 6,590% | 4,263% | 3,73% | 5,805% | 5,630% | 7,862% | 5,212% | 7,016% |
| T | 9,056% | 7,244% | 6,154% | 4,632% | 4,336% | 5,276% | 5,623% | 3,314% | 7,691% | 3,966% | 6,79% | 6,862% | 4,953% | 8,750% | 5,727% | 9,184% |
| u | 2,758% | 6,311% | 4,166% | 2,927% | 3,639% | 3,183% | 3,011% | 3,235% | 1,919% | 2,347% | 1,99% | 1,979% | 4,562% | 5,008% | 2,160% | 1,224% |
| w | 0,978% | 1,838% | 0,846% | 1,138% | 1,575% | 1,904% | 2,097% | 0,959% | 2,415% | 0,034% | 2,85% | 2,332% | 2,437% | 2,250% | 5,344% | 2,032% |
| w | 2,360% | 0,049% | 1,921% | 0,017% | 0,037% | 0 | 0,033% | 0 | 0,142% | 4,549% | 1,52% | 0,069% | 0 | 0,094% | 0,016% | 0,072% |
| X | 0,150% | 0,427% | 0,034% | 0,215% | 0,253% | 0 | 0,003% | 0 | 0,159% | 0,019% | 0,036% | 0,028% | 0,046% | 0,031% | 0,027% | 0,115% |
| y | 1,974% | 0,128% | 0,039% | 1,008% | 0,006% | 0 | 0,020% | 3,336% | 0,708% | 3,857% | 0,035% | 0,698% | 0,900% | 1,745% | 1,043% | 2,319% |
| z | 0,074% | 0,326% | 1,134% | 0,467% | 0,470% | 0,494% | 1,181% | 1.500% | 0,070% | 5,620% | 1,39% | 0,034% | 0 | 0,051% | 1,599% | 5,251% |
| A | ~ 0% [ potrzebne źródło ] | 0,486% | 0 | ~0% | 0,072% | 0 | 0,635% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| A | ~0% | 0,051% | 0 | 0 | 0,562% | 0 | ~0% | ~0% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| A | ~0% | 0 | 0 | 0,502% | 0,118% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1,799% | 0 | 0,867% | 4,208% |
| A | ~0% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1,34% | 0 | 0 | 1,190% | ~0% | 0,003% | 0 | 0 |
| A | ~0% | 0 | 0,578% | 0 | 0 | 0 | 0 | 0 | 1,80% | 0 | 0 | 0 | 0 | 3,577% | 0 | 0 |
| A | 0 | 0 | 0 | 0 | 0,733% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| A | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1,021% | 0 | 0 | 0 | 0 | 0 | 0 |
| ć | ~ 0% [ potrzebne źródło ] | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0,872% | 0,867% | 0 | 0 | 0 |
| œ | ~0% | 0,018% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| C | ~0% | 0,085% | 0 | ~0% | 0,530% | 0 | 0 | 1,156% | 0 | 0 | 0 | 0 | ~0% | 0 | 0 | 0 |
| C | 0 | 0 | 0 | 0 | 0 | 0,657% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| C | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0,448% | 0 | 0 | 0 | 0 | 0 | 0 |
| C | ~0% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0,462% | 0 |
| D | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0,015% | 0 |
| D | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 4,393% | 0 | 0 | 0 |
| mi | ~ 0% [ potrzebne źródło ] | 0,271% | 0 | ~0% | 0 | 0 | 0,263% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| mi | ~ 0% [ potrzebne źródło ] | 1,504% | 0 | 0,433% | 0,337% | 0 | 0 | 0 | 0 | ~0% | 0 | 0 | 0,647% | 0 | 0,633% | 4,072% |
| mi | 0 | 0,218% | 0 | 0 | 0,450% | 0 | ~0% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| mi | ~ 0% [ potrzebne źródło ] | 0,008% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| mi | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1,131% | 0 | 0 | 0 | 0 | 0 | 0 |
| mi | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1,222% | 0 |
| G | 0 | 0 | 0 | 0 | 0 | 0,691% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| G | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1,125% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| H | 0 | 0 | 0 | 0 | 0 | 0,022% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| I | 0 | 0,045% | 0 | 0 | 0 | 0 | ~0% | ~0% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| I | 0 | 0 | 0 | 0 | 0 | 0 | (0,030%) | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| I | 0 [ potrzebne źródło ] | 0 | 0 | 0,725% | 0,132% | 0 | 0,030% | 0 | 0 | 0 | 0 | 0 | 1,570% | 0 | 1,643% | 0,710% |
| I | ~ 0% [ potrzebne źródło ] | 0,005% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| I | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 5,114%* | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| J | 0 | 0 | 0 | 0 | 0 | 0,055% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| Ł | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1,746% | 0 | 0 | 0 | 0 | 0 | 0 |
| ľ | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ~0% | 0 |
| N | ~ 0% [ potrzebne źródło ] | 0 | 0 | 0,311% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| N | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0,185% | 0 | 0 | 0 | 0 | 0 | 0 |
| N | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0,007% | 0 |
| O | 0 | 0 | 0 | 0 | 0 | 0 | 0,002% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ö | ~0% | 0 | 0,443% | 0 | 0 | 0 | 0 | 0,777% | 1,31% | 0 | 0 | 0 | 0,777% | 0,444% | 0 | 1,251% |
| ô | ~0% | 0,023% | 0 | 0 | 0,635% | 0 | ~0% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ó | 0 [ potrzebne źródło ] | 0 | 0 | 0,827% | 0,296% | 0 | ~0% | 0 | 0 | 0,823% | 0 | 0 | 0,994% | 0 | 0,024% | 1,145% |
| ő | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1,105% |
| õ | 0 [ potrzebne źródło ] | 0 | 0 | 0 | 0,040% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ø | ~0% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0,939% | 0 | 0 | 0 | 0 |
| R | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0,380% | 0 |
| S | 0 | 0 | 0 | 0 | 0 | 0,385% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| S | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1,780% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| S | 0 [ potrzebne źródło ] | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0,683% | 0 | 0 | 0 | 0 | 0 | 0 |
| S | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ~0% | 0,688% | 0 |
| SS | 0 | 0 | 0,307% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| T | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0,006% | 0 |
| þ | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1,455% | 0 | 0 | 0 |
| u | 0 | 0,058% | 0 | 0 | 0 | 0 | (0,166%) | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| u | 0 [ potrzebne źródło ] | 0 | 0 | 0,168% | 0,207% | 0 | 0,166% | 0 | 0 | 0 | 0 | 0 | 0,613% | 0 | 0,045% | 0,320% |
| u | ~0% | 0,060% | 0 | 0 | 0 | 0 | ~0% | ~0% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ŭ | 0 | 0 | 0 | 0 | 0 | 0,520% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| u | ~0% | 0 | 0,995% | 0,012% | 0,026% | 0 | 0 | 1,854% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0,683% |
| ű | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0,145% |
| ů | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0,204% | 0 |
| ý | 0 | 0 | 0 | ~0% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0,228% | 0 | 0,995% | 0 |
| ź | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0,061% | 0 | 0 | 0 | 0 | 0 | 0 |
| ż | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0,885% | 0 | 0 | 0 | 0 | 0 | 0 |
| ż | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ~0% | 0,721% | 0 |
*Patrz İ i bez kropki I .
Poniższy rysunek ilustruje rozkład częstotliwości 26 najpopularniejszych liter łacińskich w niektórych językach. Wszystkie te języki używają podobnego alfabetu zawierającego ponad 25 znaków.
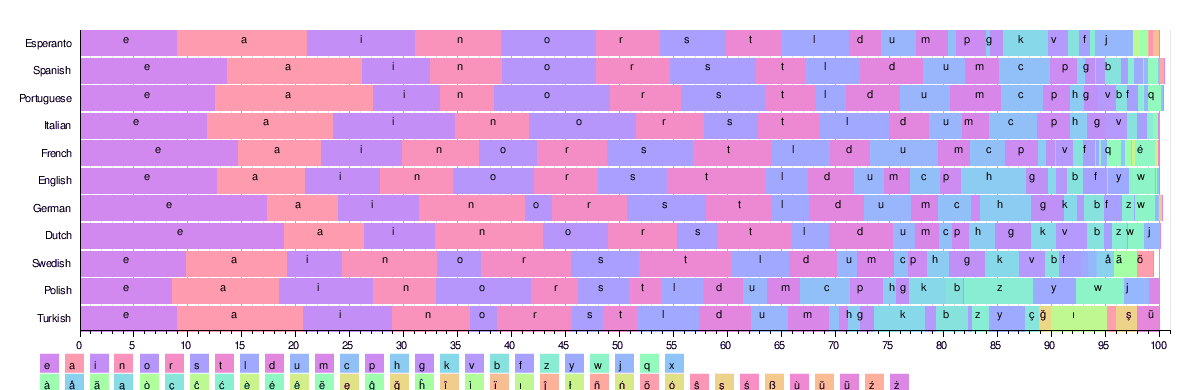
W oparciu o te tabele równoważne wyniki „ etaoin shrdlu ” dla każdego języka są następujące:
- francuski: „esaitn ruoldc”; (Indoeuropejskie: kursywa; tradycyjnie używa się „esartinulop”, częściowo ze względu na łatwość wymowy)
- hiszpański: „eaosrn idltcm”; (indoeuropejskie: kursywa)
- Portugalski: „aeosri dmntcu” (indoeuropejski: kursywa)
- włoski: „eaionl rtscdu”; (indoeuropejskie: kursywa)
- Esperanto: „aieonl srtkju” (język sztuczny - leksykalny pod wpływem języków indoeuropejskich, głównie romański, germański)
- Niemiecki: „ensria tdhulg”; (indoeuropejski: germański)
- szwedzki: „eanrts ildomk”; (indoeuropejski: germański)
- turecki: „aeinrl ıdkmyt”; (turecki)
- niderlandzki: „enatir odslgv”; (indoeuropejski: germański)
- polski: 'aioezn rwstcy'; (indoeuropejski: bałtosłowiański)
- duński: „erntai dslogk”; (indoeuropejski: germański)
- islandzki: „arnies tulðgm”; (indoeuropejski: germański)
- fiński: „aintes loukäm”; (uralski: fiński)
- czeski: „aeonit vsrldk”; (indoeuropejski: bałtosłowiański)
- węgierski: „eatlsn kizroá”; (Uralski: ugrofiński)
Zobacz też
- Częstotliwość liter arabskich
- Lingwistyka korpusowa
- Układ klawiatury Dvoraka
- Częstotliwość słów w języku angielskim
- Etaoin shrdlu
- RSTLNE ( koło fortuny )
Notatki wyjaśniające
Linki zewnętrzne
- Lewand, Robert Edward. „Matematyka kryptograficzna” . strony.central.edu. Zarchiwizowane od oryginału w dniu 2007-04-02.
- „Kilka przykładów rankingów częstotliwości liter w niektórych popularnych językach” . www.bckelk.org.uk.
- „Wizualizacja mapy cieplnej JavaScript przedstawiająca częstotliwości liter w tekstach na różnych układach klawiatury” . www.patrick-wied.at.
- Norvig, Piotr. „Zaktualizowana wersja pracy Mayznera przy użyciu zestawu danych Google Books Ngrams” . norvig.com.
- Częstotliwość liter — simia.net
Przydatne tabele
Przydatne tabele dla częstotliwości pojedynczych liter, dwugramów, trygramów, tetragramów i pentagramów na podstawie 20 000 słów, które uwzględniają kombinacje długości słowa i pozycji litery dla słów o długości od 3 do 7 liter:
- Mayzner MS; Tresselt, ja; Wolin, BR (1965). „Tabele liczby pojedynczych liter i cyfr dla różnych kombinacji długości słowa i pozycji liter”. Dodatki do monografii psychonomicznej . 1 (2): 13–32. OCLC 639975358 .
- Mayzner MS; Tresselt, ja; Wolin, BR (1965). „Tabele częstotliwości trygramów dla różnych kombinacji długości słowa i pozycji litery”. Dodatki do monografii psychonomicznej . 1 (3): 33–78.
- Mayzner MS; Tresselt, ja; Wolin, BR (1965). „Tabele zliczeń częstotliwości tetragramów dla różnych kombinacji długości słowa i pozycji liter”. Dodatki do monografii psychonomicznej . 1 (4): 79–143.
- Mayzner MS; Tresselt, ja; Wolin, BR (1965). „Tabele zliczeń częstotliwości pentagramów dla różnych kombinacji długości słowa i pozycji liter” . Dodatki do monografii psychonomicznej . 1 (5): 144–190.