Niechlujna tożsamość
W językoznawstwie niechlujna tożsamość jest właściwością interpretacyjną , którą można znaleźć w elipsie czasownika , w której tożsamość zaimka w elided VP (fraza czasownikowa) nie jest identyczna z poprzednikiem VP.
Na przykład język angielski pozwala na pomijanie PZ, jak w przykładzie (1). Elid VP można interpretować na co najmniej dwa sposoby, w następujący sposób:
- Czytanie „ścisłe” : zdanie (1) jest interpretowane jako (1a), gdzie zaimek his oznacza ten sam desygnat zarówno w poprzednim VP, jak i pominiętym VP. W (1a) zaimek jego odnosi się do Jana zarówno w pierwszym, jak i drugim zdaniu . Odbywa się to poprzez przypisanie tego samego indeksu Janowi i obu „jego” zaimkom. Nazywa się to odczytem „ścisłej tożsamości”, ponieważ pominięty VP jest interpretowany jako identyczny z poprzednikiem VP.
- „Niechlujne” czytanie : zdanie (1) jest interpretowane jako (1b), gdzie zaimek jego odnosi się do Jana w pierwszym zdaniu, ale zaimek jego w drugim zdaniu odnosi się do Boba. Odbywa się to poprzez przypisanie innego indeksu zaimkowi jego w obu zdaniach. W pierwszym zdaniu zaimek jego jest indeksowany razem z Johnem, w drugim zdaniu zaimek jego jest indeksowany razem z Bobem. Nazywa się to odczytem „niechlujnej tożsamości”, ponieważ pominięta VP nie jest interpretowana jako identyczna z poprzednią VP.
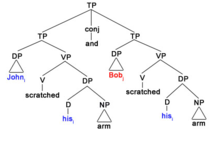
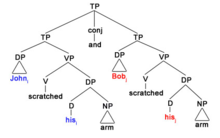
1) John podrapał się w ramię i Bob też. A. Ścisłe czytanie : John i podrapał się po ramieniu i Bob j [podrapał się po ramieniu]. B. Niechlujne czytanie : John i podrapał się w ramię i Bob j [podrapał się w ramię ].
Historia
Dyskusja na temat „niechlujnej tożsamości” wśród lingwistów sięga artykułu Johna Roberta Rossa z 1967 r., w którym Ross zidentyfikował dwuznaczność interpretacyjną w pominiętym zdaniu czasownikowym we wcześniej podanym zdaniu 1) znajdującym się we wstępie. Ross próbował bez powodzenia wyjaśnić „niechlujną” tożsamość za pomocą ściśle składniowych relacji strukturalnych i doszedł do wniosku, że jego teorie przewidywały zbyt wiele niejasności.
Lingwista Lawrence Bouton (1970) jako pierwszy opracował składniowe wyjaśnienie słowa VP-Deletion, powszechnie określanego przez współczesnych lingwistów jako VP – wielokropek . Teoria VP-Deletion Bouton i obserwacja niechlujnej tożsamości przez Rossa posłużyły jako ważny fundament dla lingwistów.
W ciągu następnej dekady nastąpiło wiele postępów, które dostarczyły lingwistom teoretycznego rusztowania niezbędnego do rozwiązywania problemów „niechlujnej tożsamości” aż do dnia dzisiejszego. Najbardziej godne uwagi z tych postępów są reguła usuwania VP-Deletion Lawrence’a Boutona (1970), „Reguła pochodnej VP” Barbary Partee (1975) oraz „Podejście do usuwania” Ivana Saga (1976), oparte na regule pochodnej-VP . Wszystkie teorie wykraczające poza początkowe odkrycie Rossa wykroczyły poza analizy oparte na obserwacjach relacji strukturalnych, często przy użyciu formy logicznej i formy fonetycznej aby uwzględnić przypadki niechlujnej i ścisłej tożsamości. Podejście polegające na usuwaniu (pochodne VP), w połączeniu z wykorzystaniem składników formy logicznej (LF) i formy fonetycznej (PF) do składni , jest jedną z najczęściej stosowanych do tej pory analiz składniowych niechlujnej tożsamości.
Ćwiczenie
model Y
Model ten reprezentuje poziom interfejsu systemu fonologicznego i systemu interpretacyjnego, które dają nam osądy formy i znaczenia struktury D. Wcześni teoretycy zdawali się sugerować, że forma fonetyczna i forma logiczna to dwa różne podejścia do wyjaśnienia pochodzenia wielokropka VP.
Analiza usunięcia w PF (forma fonetyczna).
Uczeni tacy jak Noam Chomsky (1955), Ross (1969) i Sag (1976) zasugerowali, że procesem odpowiedzialnym za wielokropek VP jest reguła usuwania składni stosowana na poziomie PF, proces ten nazywa się usuwaniem VP.
Hipoteza delecji PF zakłada, że pominięte VP jest w pełni reprezentowane składniowo, ale usunięte w komponencie fonologicznym między SPELLOUT i PF. Sugeruje to, że usuwanie VP jest procesem, który generuje niechlujne tożsamości, ponieważ współindeksacja musi zachodzić w odniesieniu do warunków wiążących .
Przykład
2.i) John zje swoje jabłko, a Sam też [VPØ]. 2.ii) [Jan i zje jego jabłko ] i [Sam j zje jego jabłko ].
Patrząc na przykład 2.i), usunięcie VP jest powodem wyprowadzenia zerowego VP. Przed usunięciem, jak widać w przykładzie 2.ii), zdanie byłoby w rzeczywistości odczytywane jako „Jan zje swoje jabłko, a Sam też zje swoje jabłko”. Zdania [Jan zje swoje jabłko] i [Sam zje swoje jabłko] mają identyczne VP w tym sensie, że mają taką samą strukturę składową , więc drugie zdanie można usunąć, ponieważ jest identyczne z poprzednim VP.
Przechodząc teraz do współindeksacji, to zdanie zawiera dwa składniki połączone spójnikiem „ i”. Każda klauzula jest niezależną kompletną strukturą zdania, więc przypuszczalnie każdy zaimek współindeksowałby swój desygnat w swoim składniku, aby zachować zgodność z wiążącymi teoriami. Przy tej współindeksacji, zilustrowanej w przykładzie 2. ii), powstaje niechlujny odczyt.
Jednak biorąc pod uwagę przypadki wrażliwe na wiążące teorie, oczekiwane ścisłe odczytanie zdania 3) naruszyłoby wiążącą zasadę A. Zgodnie z tą zasadą anafora musi być związana w swojej domenie wiążącej, co oznacza, że musi być związana w tej samej klauzuli, co jego referencja.
3) John obwiniał siebie, a Bill obwiniał siebie
Oczekiwana ścisła lektura:
3.i) John i [VP obwiniał się i ], a Bill j [VP obwiniał się i ]
Oczekiwany niechlujny odczyt:
3.ii) John i [VP obwiniał się i ], a Bill j [VP obwiniał się j ]

Biorąc to pod uwagę, obserwuje się, że w zdaniach takich jak ten trudno jest uzyskać ścisłe odczytanie, ponieważ jeśli sama anafora w wykreślonym VP jest współindeksowana z „John”, naruszałoby to Teorię Wiązania A, ponieważ są one w oddzielnych klauzulach . Relacje poleceń C są reprezentowane przez kodowanie kolorami w drzewie składni. Jak pokazano na diagramie drzewa i zilustrowano na zielono, „John i ” c-dowodzi „sobą i ” w pierwszym VP. 'Bill j ' z drugiej strony c-dowodzi 'sobą j ' w drugim VP, oznaczony kolorem pomarańczowym. Ze względu na domeny wiążące, DP najbliższe anaforom muszą być tymi, z którymi się wiążą i współindeksują. Dlatego „Jan i ” nie może nie dowodzić „sobą j ” w drugim VP, jak pokazano na podstawie różnicy w kodowaniu kolorami. W konsekwencji Teoria Wiązania A byłaby naruszona, gdyby współindeksacja przykładu 2.i) generowała ścisłe odczytanie. W związku z tym hipoteza usunięcia PF generuje niechlujne odczyty, ponieważ traktuje wyeliminowane VP jako identyczne struktury z poprzednimi VP, a współindeksacja jest ograniczona lokalizacją.
Analiza kopiowania w LF (forma logiczna).
Według Carniego problem niechlujnej tożsamości można wyjaśnić za pomocą hipotezy kopiowania LF. Hipoteza ta głosi, że przed SPELLOUT, pominięty VP nie ma struktury i istnieje jako pusty lub zerowy VP (w przeciwieństwie do hipotezy usunięcia PF, która twierdzi, że pominięty VP ma strukturę w całym wyprowadzeniu). Tylko kopiując strukturę z poprzednika VP, ma strukturę w LF. Te procesy kopiowania zachodzą potajemnie ze SPELLOUT do LF.
Zgodnie z kopiowaniem LF niejednoznaczność występująca w niechlujnej tożsamości wynika z różnych kolejności reguł kopiowania zaimków i czasowników. Rozważ następujące wyprowadzenia niechlujnego czytania i ścisłego czytania dla zdania (4), używając reguły kopiowania ukrytego wiceprezesa i reguły kopiowania anafory:
4) Calvin uderzy siebie i Otto też [vp Ø].
Niechlujne czytanie
W niechlujnym czytaniu zasada kopiowania VP ma zastosowanie jako pierwsza, jak widać w zdaniu 5). Reguła kopiowania VP kopiuje VP z poprzednika do pustego VP:
Ukryta reguła kopiowania VP
5) Calvin [uderzy się] i Otto też [udeży się].
Zgodnie z regułą kopiowania VP obowiązuje reguła kopiowania anafory, jak widać w zdaniu 6). Reguła kopiowania anafor, która jest powiązana z klauzulami, kopiuje NP do anafor w ramach tej samej klauzuli:
Ukryta reguła kopiowania anafory
6) Calvin [uderzy Calvina] i Otto też [uderzy Otto].
Ścisłe czytanie
W ścisłym czytaniu stosowanie tych zasad następuje w odwrotnej kolejności. Dlatego reguła kopiowania anafory jest stosowana jako pierwsza. Ze względu na to, że puste VP nie zawiera anafory, nie można do niego skopiować NP „Otto”. Proces ten można zobaczyć w zdaniu 7):
Ukryta reguła kopiowania anafory
7) Calvin [uderzy Calvina] i Otto też [vp Ø].
Zgodnie z regułą kopiowania anafor, obowiązuje reguła kopiowania VP i tworzy zdanie w 8):
Ukryta reguła kopiowania VP
8) Calvin [uderzy Calvina] i Otto [uderzy Calvina] też.
Wyprowadzenie użyte w tej hipotezie kopiowania LF można znaleźć tutaj .
Połączenie PF i LF
Opierając się na pracach Bouton (1970) i Ross (1969), Barbara Partee (1975) opracowała jedno z najważniejszych i najbardziej wpływowych dotychczas podejść do wyjaśniania VP, Derived VP-Rule , która wprowadza zerową regułę VP . operator na poziomie VP. Wkrótce potem Ivan A. Sag (1976) opracował podejście Deletion Derived VP , a Edwin S. Williams (1977) opracował podejście Interpretive Derived VP . Zasady te są nadal stosowane przez wielu dzisiaj.
Pochodna reguła VP:
Według Williamsa (1977), Derived VP Rule przekształca VP w strukturze powierzchni na właściwości zapisane w notacji lambda. Jest to bardzo ważna zasada, na której budowano przez lata, aby nadać sens niechlujnej tożsamości. Ta reguła VP jest używana przez wielu lingwistów jako podstawa ich reguł elipsy.
Podejście VP oparte na delecjach:
Ivan Sag zaproponował dwie formy logiczne, z których jedną zaimek koreferencjalny zastępuje zmienna związana . Prowadzi to do reguły interpretacji semantycznej, która bierze zaimki i zamienia je na zmienne związane. Reguła ta jest skracana jako Pro→BV, gdzie „Pro” oznacza zaimek, a „BV” oznacza zmienną związaną.
Przykład prostego zdania
9) [Betsy kocham ją i psa]
Ścisłe odczytanie zdania 9) jest takie, że „Betsy kocha własnego psa”. Zastosowanie Pro→BV wyprowadza zatem zdanie z 9.i):
9.i) [Betsy kocham jej psa j (lub x)]
Gdzie jej j to ktoś inny, a x to czyjś pies
Złożony przykład
10) Betsy i kocham jej psa i Sandy j też kocha ∅
gdzie ∅ = kocha swojego psa
Ścisłe czytanie
Ścisłe odczytanie punktu 10) brzmi: „Betsy kocha psa Betsy, a Sandy też kocha psa Betsy”, co oznacza, że ∅ to PZ, które zostało usunięte. Jest to przedstawione w następującym zdaniu:
10.i) Betsy i λx (x kocha ją i pies) i Sandy λy (y kocha ją i pies)
VP, które są reprezentowane przez λx i λy, są składniowo identyczne. Z tego powodu ten, który jest sterowany c (λy), może zostać usunięty.
To wtedy tworzy:
10.ii) Betsy i kocham jej psa i Sandy j też kocha ∅
Niechlujne czytanie
Niechlujne odczytanie tego zdania brzmi: „Betsy kocha psa Betsy, a Sandy kocha psa Sandy”. Oznacza to, że obie kobiety kochają własnego psa. Jest to przedstawione w następującym zdaniu:
10.iii) Betsy i λx (x kocha swojego psa ) i Sandy j λy (y kocha swojego j psa)
Ponieważ klauzule osadzone są identyczne, logika tej formy polega na tym, że zmienna x musi być powiązana z tą samą frazą rzeczownikową w obu przypadkach. Dlatego „Betsy” zajmuje pozycję dowódczą, która determinuje interpretację drugiej klauzuli.
Regułę Pro → BV, która zamienia zaimki na zmienne związane, można zastosować do wszystkich zaimków.
Pozwala to na to, aby zdanie w 10.iii) brzmiało:
10.iv) Betsy i λx (x kocha psa x) i Sandy j λy (y kocha psa y)
Innym sposobem, w jaki VP może być syntaktycznie identyczny, jest to, że jeśli λx(A) i λy(B) gdzie każdy przypadek x w A ma odpowiadający mu przypadek y w B. Tak więc, jak w powyższym przykładzie, dla wszystkich przypadków x istnieje jest odpowiednią instancją y i dlatego są one identyczne, a VP, któremu wydano komendę c, można usunąć.
Wyprowadzenie krok po kroku
W podejściu Saga VP Ellipsis jest analizowane jako usunięcie, które ma miejsce pomiędzy S-structure (Shallow Structure) a PF (Surface Structure). Uważa się, że usuniętą VP można odzyskać na poziomie LF z powodu utrzymywania wariancji alfabetycznej między dwoma wyrażeniami λ. W tym podejściu do usuwania niechlujna tożsamość jest możliwa po pierwsze dzięki indeksowaniu anafor, a następnie dzięki zastosowaniu reguły przepisywania zmiennych.
Poniżej znajduje się wyprowadzenie krok po kroku, biorąc pod uwagę zarówno formy fonetyczne, jak i logiczne, wyjaśniające niechlujne odczytanie zdania „John obwiniał siebie i Bill też”.
mapowanie LF
Struktura głęboka do struktury powierzchniowej:
11) John i [ VP obwiniał się] i Bill j [ VP obwiniał się] też.
W tym zdaniu wiceprezes [obwinia się] są obecni, ale nie odnoszą się jeszcze do żadnego tematu. W zdaniu 12) stosowana jest reguła pochodnych VP, przepisując te VP za pomocą notacji lambda.
Pochodna reguła VP
12) John i [ VP λx ( x obwinia się)], Bill j [ VP λy ( y obwinia się)] też.
Pochodna reguła VP wyprowadziła dwa VP zawierające oddzielne operatory λ ze zmiennymi referencyjnymi związanymi w każdej klauzuli poprzedzającej. Następna reguła, Indeksowanie, współindeksuje anafory i zaimki do ich podmiotów.
Indeksowanie
13) John i [ VP λx(x obwiniaj go i )], Bill j [ VP λy(y obwiniaj go j )] też.
Jak widzimy, anafory zostały zindeksowane do odpowiednich NP. Wreszcie, reguła przepisywania zmiennych zastępuje zaimki i anafory zmiennymi w formie logicznej.
Pro-->BV
Forma logiczna:
14) Jan i [ VP λx(x wina x)], Bill j [ VP λy (y wina y)] też.
Mapowanie PF
Struktura głęboka do struktury powierzchniowej:
15) John [ VP obwinia się] i Bill [ VP obwinia się] też.
Tutaj widzimy, że zarówno John, jak i Bill poprzedzają tego samego wiceprezesa, [obwinia się]. Należy zauważyć, że wszelkie znaczenie, w tym przypadku podmiot, do którego odnosi się „sam” Anafora, jest określone w LF, a zatem pominięte w formie fonetycznej.
Usuwanie VP
16) John [ wiceprzewodniczący obwiniał się] i Bill ____ też.
Następuje usunięcie VP, co w efekcie usuwa VP [obwinia się] z drugiej klauzuli Bill [obwinia się]. Ponownie, ważne jest, aby pamiętać, że ta delecja zachodzi ściśle na poziomie fonetycznym, a zatem [obwinia się] nadal istnieje w składowej LF, mimo że została usunięta w PF.
Wspieraj
Forma fonetyczna:
17) John [ VP obwiniał się], a Bill też ____ .
Na koniec zaimplementowano Do-Support, wypełniając pustą przestrzeń utworzoną przez VP Deletion za pomocą did . To ostatni krok, który występuje w PF, pozostawiając zdanie do fonetycznej realizacji jako „John obwiniał siebie, a Bill też”. Ze względu na zasady wprowadzone w składowej LF derywacji, chociaż did fonetycznie zastąpił VP [obwinia siebie], jego znaczenie jest takie samo, jak ustalono w LF. Zatem „Bill też to zrobił” można niechlujnie zinterpretować jako „Bill obwiniał siebie”, jak w „Bill obwinił Billa”.
Podejście VP wywodzące się z interpretacji
W swoim podejściu do problemu niechlujnej tożsamości Williams (1977) przyjmuje również regułę pochodnej VP. Sugeruje również, że anafory i zaimki są przepisywane jako zmienne w LF przez zmienną regułę przepisywania. Następnie, korzystając z reguły VP, zmienne te są następnie kopiowane do pominiętego VP. Stosując się do tego podejścia, możliwe są zarówno niechlujne, jak i ścisłe odczyty. Poniższe przykłady przejdą przez wyprowadzenie zdania 18.i) jako niechlujne odczytanie:
Niechlujne czytanie
18.i) John odwiedza swoje dzieci w niedzielę i Bill też [ VP ∅].
Jak widać w tym zdaniu, VP nie zawiera żadnej struktury. W zdaniu 19.i) stosowana jest reguła pochodnej VP, która przepisuje VP przy użyciu notacji lambda:
Pochodna reguła VP
19.i) John [ VP λx (x odwiedza swoje dzieci)] i Bill również [ VP ∅].
Następnie reguła przepisywania zmiennych przekształca zaimki i anafory w zmienne w LF:
Reguła przepisywania zmiennych
20.i) John [ VP λx (x odwiedza dzieci x)] i Bill również [ VP ∅].
Reguła VP następnie kopiuje strukturę VP do pominiętego VP:
Reguła VP
21.i) John [ VP λx (x odwiedza dzieci x)] i Bill również [ VP λx (x odwiedza dzieci x)].
Główna różnica między niechlujnym a ścisłym odczytem polega na regule zmiennego przepisywania. Obecność tej reguły pozwala na niechlujny odczyt, ponieważ zmienne są powiązane operatorem lambda w ramach tego samego VP. Konwertując zaimek his w 20.i) na zmienną, a kiedy VP zostanie skopiowane do pominiętego VP w zdaniu 21.i), zmienna w pominiętym VP może być związana przez Billa. Dlatego, aby uzyskać ścisłe odczytanie, ten krok jest po prostu pomijany.
Ścisłe czytanie
18.ii) John odwiedza swoje dzieci w niedzielę i Bill też [ VP ∅].
VP jest przepisywane przy użyciu notacji lambda:
Pochodna reguła VP
19.ii) John [ VP λx (x odwiedza swoje dzieci)] i Bill też [ VP ∅].
Struktura VP jest kopiowana do pomijanego VP:
Reguła VP
21.ii) John [ VP λx (x odwiedza swoje dzieci)] i Bill również [ VP λx (x odwiedza swoje dzieci)].
Ze względu na fakt, że zaimek jego jest już współindeksowany z Johnem i nie został przepisany jako zmienna przed skopiowaniem do wykreślonego VP, nie ma możliwości, aby był związany przez Billa. Dlatego ścisłe odczytanie jest wyprowadzane przez pominięcie reguły przepisywania zmiennych.
Teoria przesunięcia centrowania
Ideę „centrowania”, zwaną też „skupieniem”, omawiali liczni językoznawcy, m.in. A. Joshi, S. Weinstein, B. Grosz. Teoria ta opiera się na założeniu, że w rozmowie obaj uczestnicy podzielają psychologiczne skupienie się na bycie, który jest centralny dla ich dyskursu. Hardt (2003), posługując się tym centrującym podejściem teoretycznym, sugeruje, że w dyskursie przesunięcie punktu ciężkości z jednego podmiotu na inny umożliwia występowanie niechlujnych odczytów.
W poniższych dwóch przykładach indeks górny * reprezentuje aktualny przedmiot dyskursu, podczas gdy indeks dolny * oznacza podmiot, który odnosi się do przedmiotu dyskursu. Rozważ następujące dwa przykłady:
Ścisłe czytanie

22) John* podrapał się * w ramię, a Bob podrapał się * w ramię
W powyższym przykładzie nie ma przesunięcia od początkowego punktu skupienia, dlatego powstaje ścisłe znaczenie, w którym zarówno John, jak i Bob podrapali ramię Johna, ponieważ John jest miejscem, w którym koncentruje się i pozostaje przez cały dyskurs. I odwrotnie, przesunięcie punktu ciężkości z początkowego punktu ciężkości dyskursu, jak w poniższym przykładzie, prowadzi do niechlujnego czytania.
Niechlujne czytanie

23) John* podrapał się * w ramię, a Bob* podrapał się * w ramię
Teraz pojawia się niechlujne odczytanie zdania, w którym John podrapał się w ramię (ramię Johna), a Bob podrapał się w ramię (ramię Boba). Przesunięcie punktu ciężkości włączyło Boba jako rzeczownik główny, co pozwala zaimkowi jego odnosić się do najbliższego indeksu górnego *, w tym przypadku Boba.
Jest to uproszczone wyjaśnienie teorii centrowania. Podejście to można dokładniej zbadać w artykule Hardta z 2003 roku. Chociaż poza zakresem tej dyskusji, użycie Teorii Centrowania przez Hardta może również wyjaśnić zagadkę dwóch elips zaimków i zagadkę postawy dwóch zaimków, dwie zagadki, których przed Teorią Centrowania nie można było właściwie wyjaśnić.
Międzyjęzykowe implikacje niechlujnej tożsamości
Przypadki niechlujnej tożsamości zaobserwowano w wielu językach, jednak większość badań koncentrowała się na przypadkach niechlujnej tożsamości występujących w języku angielskim. Pod względem językowym niechlujna tożsamość jest analizowana jako problem uniwersalny, który można znaleźć w podstawowej strukturze składniowej, wspólnej dla wszystkich języków. Aby zapoznać się z przykładami i analizami niechlujnej tożsamości w języku innym niż angielski, takimi jak japoński , koreański i chiński , zobacz następujące artykuły w sekcji materiałów referencyjnych poniżej. Poniżej znajduje się również szczegółowe wyjaśnienie niechlujnej tożsamości w języku mandaryńskim.
Niechlujna tożsamość w języku mandaryńskim
Wsparcie Shì (是)
W ramach generatywnych argumentowano, że jawnym odpowiednikiem do -support w języku angielskim jest shì -support we współczesnym mandaryńskim. Podobnie jak do -support, shì -support pozwala na konstrukcje, które nie są w pełni rozwinięte.
Przykład
1. Zhangsan xihuan ta-de didi. Lisi ye shi. Zhangsan, podobnie jak jego młodszy brat Lisi, również „Zhangsan lubi swojego młodszego brata; Lisi też
Oczekiwana ścisła lektura:
1. i) Zhangsan lubi swojego młodszego brata, a Lisi też lubi młodszego brata Zhangsana.
Oczekiwany niechlujny odczyt:
1. ii) Zhangsan lubi swojego młodszego brata, a Lisi lubi swojego młodszego brata.
Jak wskazuje (1), zarówno ścisłe, jak i niechlujne odczyty są równie dostępne, podobnie jak w przypadku języka angielskiego.
Chociaż wsparcie shì może zastępować czasowniki stanowe we współczesnym mandaryńskim, takie jak „xihuan” (jak), nie jest kompatybilne ze wszystkimi typami czasowników. Na przykład czasowniki dotyczące czynności stojące samotnie nie zawsze są kompatybilne z shì -wsparcie.
Przykład
2. Zhangsan rurociągi-le ta-de didi. ?/?? Lisi ye shi. Zhangsan krytykować-Asp. jego młodszy brat Lisi również „Zhangsan skrytykował swojego młodszego brata; Lisi też.
Oczekiwana ścisła lektura:
2.i) Zhangsan skrytykował własnego młodszego brata. ?Lisi skrytykowała także młodszego brata Zhangsana.
Oczekiwany niechlujny odczyt:
2.ii) Zhangsan skrytykował własnego młodszego brata. ?? Lisi skrytykował własnego młodszego brata.
Jak wskazuje (2), zarówno ścisłe, jak i niechlujne odczyty są równie dostępne, jednak ocena powyższych zdań może się różnić w zależności od native speakera współczesnego mandaryńskiego.
Aby poprawić ogólną akceptowalność ścisłego i niechlujnego odczytania (2), Ai (2014) dodał przysłówki do zdania poprzedzającego.
Przykład:
3. Zhangsan henhen-de rurociągi-le ta-de didi. Lisi ye shi. Zhangsan energicznie-DE krytykować-Asp. jego młodszy brat Lisi również był „Zhangsanem energicznie krytykował swojego młodszego brata; Lisi też.
Oczekiwana ścisła lektura:
3.i) Zhangshan energicznie krytykował swojego młodszego brata. Lisi również ostro skrytykowała brata Zhangshana.
Oczekiwany niechlujny odczyt:
3.ii) Zhangsan energicznie krytykował swojego młodszego brata. ? Lisi ostro krytykował własnego młodszego brata.
Jak wskazuje (3), zarówno ścisłe, jak i niechlujne odczyty są równie dostępne, jednak według wspomnianej ankiety, native speakerzy współczesnego mandaryńskiego nadal wolą niechlujne czytanie od ścisłego. Wątpliwa jest analiza (3) oparta na dodawaniu przysłówków zgodnie z diagnostyką równego rozkładu zarówno w czytaniu ścisłym, jak i niedbałym.
Negacja we wsparciu shi
Negacja w shi-support i negacja w angielskim do-support nie działają identycznie. Poprzedzone przeczącym bu (nie), wsparcie shi nie jest gramatyczne, niezależnie od tego, czy poprzednik językowy jest twierdzący, czy negatywny.
Przykład:
4.* Ta xihuan Zhangsan. Wo bu-shi, on lubi Zhangsana, nie jestem „On lubi Zhangsana. Ja nie”.
5. * Ta bu-xihuan Zhangsan. Wo wy bu-shi on nie lubi Zhangsana Ja też nie jestem "On nie lubi Zhangsana. Ja też nie."
Jeśli jednak poprzednik językowy jest ujemny, wsparcie shi może zapewnić odczytanie negatywne, nawet jeśli wsparcie shi nie jest poprzedzone przeczącym bu ( nie ).
Przykład:
6. Ta bu-xihuan Zhangsan. Wo ty shi. on nie lubi Zhangsana, ja też jestem „On nie lubi Zhangsana. Ja też nie”.
Pytania w shi-support
Dodatkowo pytania w shi-support iw angielskim do-support nie działają identycznie. Shi nie może licencjonować wielokropka, gdy w pytaniu występuje poprzednik językowy.
Przykład:
7. O: Shei Xihuan Zhangsan? kto lubi Zhangsana „Kto lubi Zhangsana?” B: * Wo shi I być „tak”.
Śluza mandarynkowa
Trzy podstawowe właściwości niechlujnej tożsamości w sluicingu mandaryńskim obejmują: (1) komendę c (2) identyczność leksykalną między słowami-wh i (3) efekt „tego”.
C-dowodzenie
Ross (1967) zaproponował, że aby wyrażenie pominięte miało niechlujną tożsamość, zaimek odnoszący się do czytania musi być c-polecony przez jego poprzednik, jak pokazano w (8a). W przeciwnym razie niechlujna tożsamość nie jest dostępna, jak w (8b). Śluza mandaryńska jest zgodna z tym ograniczeniem w (9).
Przykład
8a. John ja wie, dlaczego mnie skarcił, i Mary też wie, dlaczego.
Oczekiwana ścisła lektura:
8a. i) Jan wie , dlaczego mnie skarcił, a Maria j wie, dlaczego mnie skarcił.
Oczekiwany niechlujny odczyt:
8a. ii) Jan wie , dlaczego został zbesztany, a Maryja wie , dlaczego ją zbesztano .
Przykład
8b. Matka Johna wie, dlaczego został skarcony, i matka Mary też wie, dlaczego.
Oczekiwana ścisła lektura:
8b. i) „ Matka Jana i wie, dlaczego został zbesztany, a matka Mary wie, dlaczego został zbesztany”.
Oczekiwany niechlujny odczyt:
8b. ii) * „Matka Jana wie, dlaczego został zbesztany, a matka Marii wie, dlaczego ją zbesztano”.
Przykład
9a. Zhangsan i bu zhidao [ta i weishenme bei ma], dan Lisi j zhidao (shi) weishenme Zhangsan nie wie, dlaczego PASS skarcił, ale Lisi wie, dlaczego „Zhangsan nie wiedział, dlaczego został skarcony, ale Lisi wie dlaczego”.
Oczekiwana ścisła lektura:
9a. i) Zhangsan nie wiedział, dlaczego został zbesztany, ale Lisi wie, dlaczego Zhangsan został zbesztany.
Oczekiwany niechlujny odczyt:
9a. ii) Zhangsan nie wiedziałem , dlaczego został zbesztany , ale Lisi j wie, dlaczego został zbesztany.
Przykład
9b. [Zhangsan-de muqin] zhidao ta weishenme bei ma, dan [lisi-de muqin] bu zhidao (shi) weishenme. Matka Zhangsan-POSS wie, dlaczego PASS skarciła, ale matka Lisi-POSS nie wie, dlaczego „Matka Zhangsana wie, dlaczego został skarcony, ale matka Lisi nie wie, dlaczego”
Oczekiwana ścisła lektura:
9b. i) Matka Zhangsana wie, dlaczego został zbesztany, ale matka Lisi nie wie, dlaczego Zhangsan został zbesztany.
Oczekiwany niechlujny odczyt:
9b. ii) *Matka Zhangsana wie, dlaczego został zbesztany, ale matka Lisi nie wie, dlaczego Lisi została zbesztana.
Wpis leksykalny między słowami-wh
Aby wyprowadzić niechlujną tożsamość, wymagana jest tożsamość „leksykalna” między jawnym korelatem wh a resztą wh, niezależnie od rozróżnienia argument-pomocnik. Tak jest również w przypadku śluzowania mandaryńskiego, dla tożsamości pomocniczej wh w (9a) i tożsamości argumentu wh w (10).
Przykład
10. Zhangsan zhidao [ shei zai rurociągi tai], dan Lisi bu zhidao shi shei. Zhangsan wie, kto PROG go krytykuje, ale Lisi nie wie, kim jest „Zhangsan wie, kto go krytykuje, ale Lisi nie wie, kto”.
Oczekiwana ścisła lektura:
10. i) Zhangsan wie, kto go krytykuje, ale Lisi nie wie, kto krytykuje Zhangsana.
Oczekiwany niechlujny odczyt:
10. ii) Zhangsan wie, kto go krytykuje, ale Lisi nie wie, kto krytykuje siebie.
Biorąc pod uwagę te leksykalne ograniczenia tożsamości, wyprowadzenie niechlujnego odczytania tożsamości przewiduje, że poprzednik wh musi być jawnie obecny, w przeciwnym razie dozwolone jest tylko ścisłe czytanie.